BambooAI
388 44What is BambooAI ?
BambooAI is a lightweight library utilizing Large Language Models (LLMs) to provide natural language interaction capabilities, much like a research and data analysis assistant enabling conversation with your data. You can either provide your own data sets, or allow the library to locate and fetch data for you. It supports Internet searches and external API interactions.
Objective
The BambooAI library is an experimental, lightweight tool that leverages Large Language Models (LLMs) to make data analysis more intuitive and accessible, even for non-programmers. Functioning like a research and data analysis assistant, it enables users to engage in natural language interactions with their data. You can supply your own data sets, or let BambooAI find and retrieve the necessary data for you. It also integrates Internet searches and an access to external APIs for broader context and utility.
By understanding your natural language inquiries about a dataset, BambooAI can autonomously generate and execute the relevant Python code for analysis and visualization. This allows users to effortlessly extract valuable insights from their data without needing to write complex code or master advanced programming concepts. Just input your dataset, pose your questions in plain English, and BambooAI provides answers along with ready-to-use visualizations if requested, to deepen your understanding of the data.
The primary aim of BambooAI is to enhance, not replace, the capabilities of analysts at every level. This library simplifies the processes of data analysis and visualization, thereby streamlining workflows. It’s designed to be relatively user-friendly, efficient, and adaptable to different users’ needs. As a supportive tool rather than the central operator, BambooAI empowers users to apply their analytical skills more effectively and boost their productivity.
Preview
Try it out in Google Colab:
![]()
A Generic Example (No dataframe required, Data downloaded from Internet):
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df, debug=False, vector_db=True, search_tool=True)
bamboo.pd_agent_converse()A Machine Learning Example using supplied dataframe:
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df, debug=True, vector_db=True, search_tool=True)
bamboo.pd_agent_converse()How it works
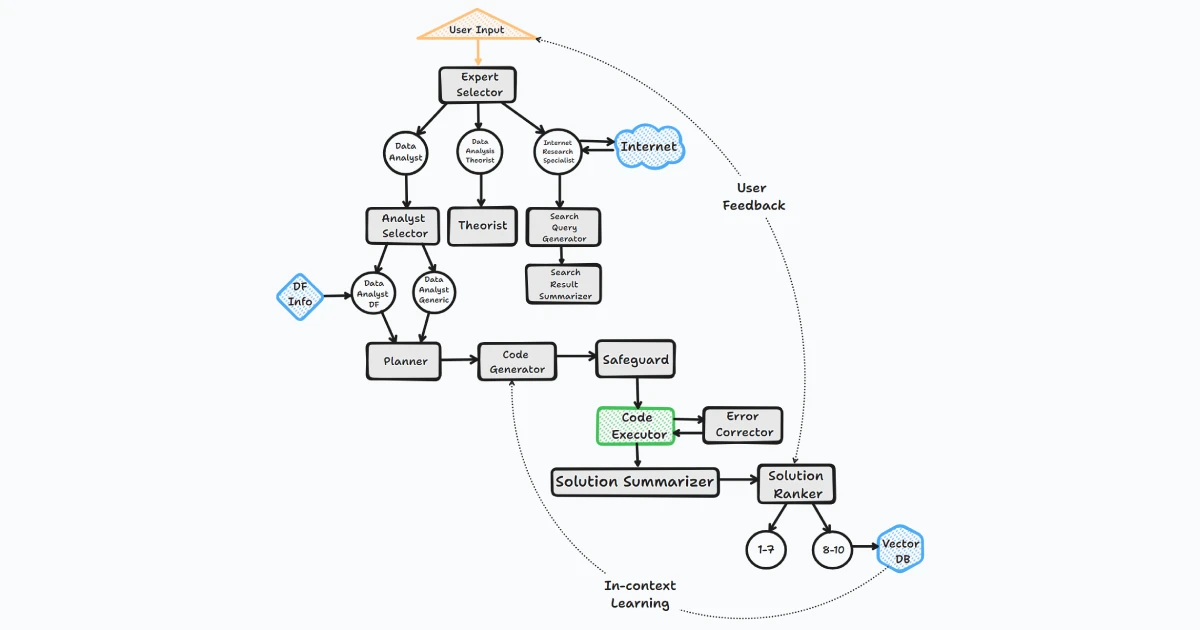
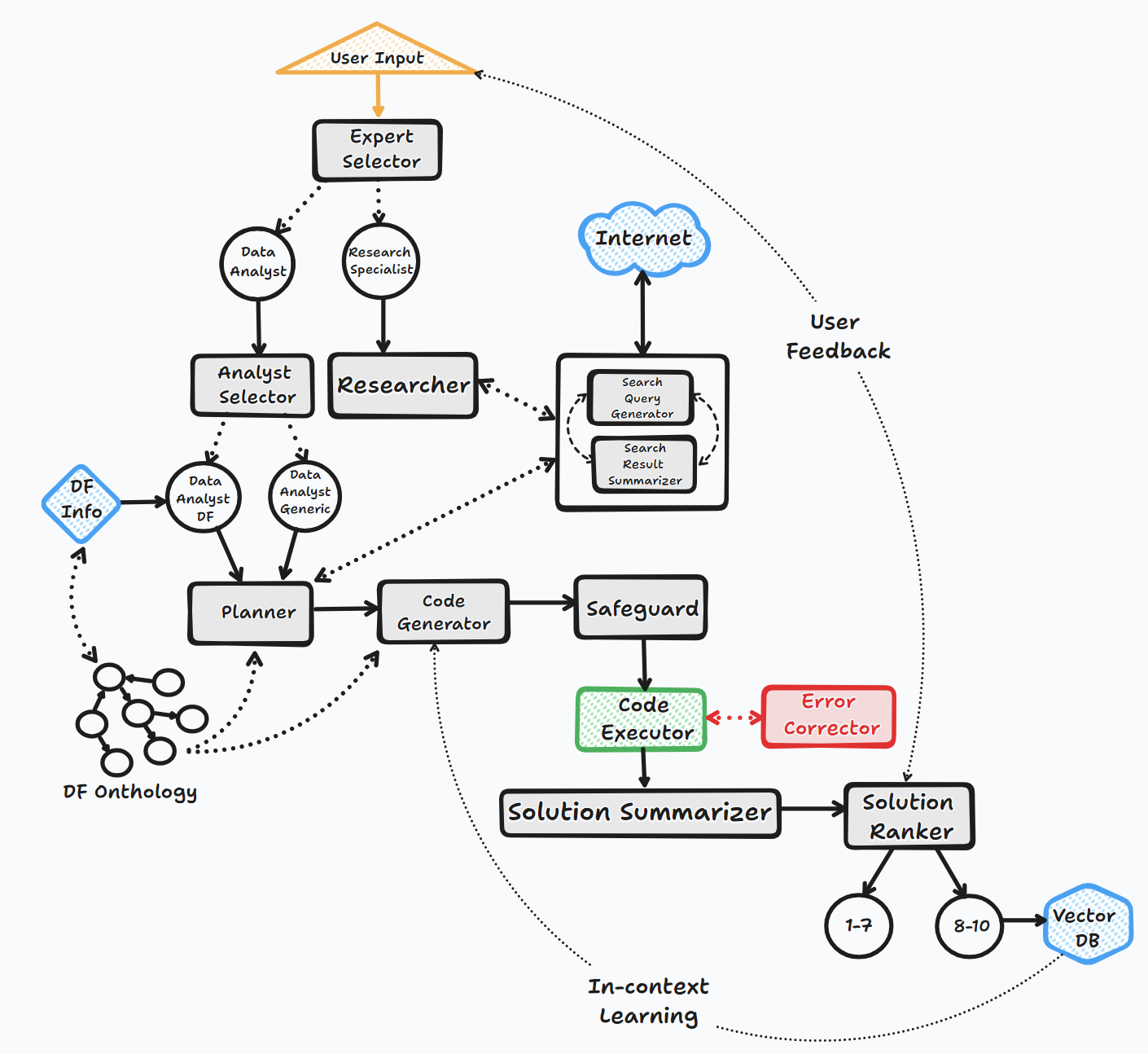
The BambooAI agent operates through several key steps to interact with users and generate responses:
1. Initiation
-
The user launches the BambooAI agent with a question.
-
If no initial question is provided, the agent prompts the user for a question or an ‘exit’ command to terminate the program.
-
The agent then enters a loop where it responds to each question provided, and upon completion, prompts the user for the next question. This loop continues until the user chooses to exit the program.
2. Task Evaluation
-
The agent stores the received question and utilizes the Large Language Model (LLM) to evaluate and categorize it.
-
The LLM determines whether the question necessitates a textual response, additional information (Google search), or can be resolved using code.
-
Depending on the task evaluation and classification the agent calls the appropriate agent.
3. Dynamic Prompt Build
-
If the question can be resolved by code, the agent determines whether the necessary data is contained within the provided dataset, requires downloading from an external source, or if the question is of a generic nature and data is not required.
-
The agent then chooses its approach accordingly. It formulates an algorithm, expressed as a task list, to serve as a blueprint for the analysis.
-
The original question is modified to align with this algorithm. The agent performs a semantic search against a vector database for similar questions.
-
Any matching questions found are appended to the prompt as examples. GPT-3.5, GPT-4 or a local OSS model is then used to generate code based on the algorithm.
4. Debugging, Execution, and Error Correction
-
If the generated code needs debugging, GPT-4 is engaged.
-
The code is executed, and if errors occur, the agent logs the error message and refers it back to the LLM for correction.
-
This process continues until successful code execution.
5. Results, Ranking, and Knowledge Base Build
-
Post successful execution, GPT-4 is used to rank the answer.
-
If the rank surpasses a set threshold, the question, answer, code, and rank are stored in the Pinecone vector database.
-
Regardless of the rank, the final answer or visualization is formatted and presented to the user.
6. Human Feedback and Loop Continuation
-
The agent seeks feedback from the user.
-
If the user validates the auto-generated ranking, the question/answer pair is stored in the vector database.
-
If not, a new execution loop begins.
Throughout this process, the agent continuously solicits user input, stores messages for context, and generates and executes code to ensure optimal results. Various AI models and a vector database are employed in this process to provide accurate and helpful responses to user’s questions.
Flow chart (General agent flow):
How to use
Installation
pip install bambooaiUsage
- Parameters
df: pd.DataFrame - Dataframe (It will try to source the data from internet, if 'df' is not provided)
max_conversations: int - Number of "user:assistant" conversation pairs to keep in memory for a context. Default=2
debug: bool - If True, the received code is sent back to the Language Learning Model (LLM) for an evaluation of its relevance to the user's question, along with code error checking and debugging.
search_tool: bool - If True, the agent will switch to a google search if the answer is not available or satisfactory.
vector_db: bool - If True, each answer will first be ranked from 1 to 10. If the rank surpasses a certain threshold (8), the corresponding question (vectorised), answer, code, and rank (metadata) are all stored in the Pinecone database. Each time a new question is asked, these records will be searched. If the similarity score is above 0.9, they will be offered as examples and included in the prompt (in a one-shot learning scenario)
exploratory: bool - If set to True, the LLM will evaluate the user's question and select an "Expert" that is best suited to address the question (experts: Internet Search Specialist, Data Analisys Theoretician, Data Analyst). For instance, if the task involves code generation/execution, it will generate a task list detailing the steps, which will subsequently be sent to the LLM as a prompt for the next action. This method is particularly effective for vague user prompts, but it might not perform as efficiently with more specific prompts. The default setting is True.
e.g. bamboo = BambooAI(df, debug=True, vector_db=True, search_tool=True, exploratory=True)
bamboo = BambooAI(df,debug=False, vector_db=False, exploratory=True, search_tool=True)Deprecation Notice (October 25, 2023):
Please note that the “llm”, “localcodemodel”, “llmswitchplan”, and “llmswitchcode” parameters have been deprecated as of v 0.3.29. The assignment of models and model parameters to agents is now handled via LLMCONFIG. This can be set either as an environment variable or via a LLMCONFIG.json file in the working directory. Please see the details below
- LLM Config
The agent specific llm configuration is stored in LLM_CONFIG environment variable, or in the “LLM_CONFIG.json file which needs to be stored in the BambooAI’s working directory. The config is in a form of JSON list of dictionaries and specifies model name, provider, temperature and max_tokens for each agent. You can use the provided LLM_CONFIG_sample.json as a starting point, and modify the config to reflect your preferences. If neither “ENV VAR” nor “LLM_CONFIG.json” is present, BambooAI will use the default hardcoded configuration that uses “gpt-3.5-turbo” for all agents.
- Prompt Templates
The BambooAI library uses default hardcoded set of prompt templates for each agent. If you want to experiment with them, you can modify the provided “PROMPT_TEMPLATES_sample.json” file, remove the “_sample from its name and store in the working directory. Subsequently, the content of the modified “PROMPT_TEMPLATES.json” will be used instead of the hardcoded defaults. You can always revert back to default prompts by removing/renaming the modified “PROMPT_TEMPLATES.json”.
- Example usage: Run in a loop
# Run in a loop remembering the conversation history
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse()- Example Usage: Single execution
# Run programaticaly (Single execution).
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse("Calculate 30, 50, 75 and 90 percentiles of the heart rate column")Environment Variables
The library requires an OpenAI API account and the API key to connect to OpenAI LLMs. The OpenAI API key needs to be stored in a OPENAI_API_KEY environment variable.
The key can be obtained from here: https://platform.openai.com/account/api-keys.
As mentioned above, the llm config can be stored in a string format in the LLM_CONFIG environment variable. You can use the content of the provided LLM_CONFIG_sample.json as a starting point and modify to your preference, depending on what models you have access to.
The Pincone vector db is optional. If you don want to use it, you dont need to do anything. If you have an account with Pinecone and would like to use the knowledge base and ranking features, you will be required to setup PINECONE_API_KEY and PINECONE_ENV envirooment variables, and set the ‘vector_db’ parameter to True. The vector db index is created upon first execution.
The Google Search is also optional. If you don want to use it, you dont need to do anything. If you have an account with Serper and would like to use the Google Search feature, you will be required to setup SERPER_API_KEY environment variable, and set the ‘search_tool’ parameter to True.
Local Open Source Models
The library currently supports the following open-source models. I have selected the models that currently score the highest on the HumanEval benchmark.
-
WizardCoder(WizardLM): WizardCoder-15B-V1.0, WizardCoder-Python-7B-V1.0, WizardCoder-Python-13B-V1.0, WizardCoder-Python-34B-V1.0
-
WizardCoder GPTQ(TheBloke): WizardCoder-15B-1.0-GPTQ, WizardCoder-Python73B-V1.0-GPTQ, WizardCoder-Python-13B-V1.0-GPTQ, WizardCoder-Python-34B-V1.0-GPTQ
-
CodeLlama Instruct(TheBloke): CodeLlama-7B-Instruct-fp16, CodeLlama-13B-Instruct-fp16, CodeLlama-34B-Instruct-fp16
-
CodeLlama Instruct(Phind): Phind-CodeLlama-34B-v2
-
CodeLlama Completion(TheBloke): CodeLlama-7B-Python-fp16, CodeLlama-13B-Python-fp16, CodeLlama-34B-Python-fp16
If you want to use a local model for a specific agent, modify the LLM_CONFIG content replacing the OpenAI model name with the local model name and change the provider value to ‘local’. eg. {"agent": "Code Generator", "details": {"model": "Phind-CodeLlama-34B-v2", "provider":"local","max_tokens": 2000, "temperature": 0}}
At present it is recommended to use local models only for code generation tasks, all other tasks like pseudo code generaration, summarisation, error correction and ranking should be still handled by OpenAI models of choice. The model is downloaded from Huggingface and cached localy for subsequent executions. For a reasonable performance it requires CUDA enabled GPU and the pytorch library compatible with the CUDA version. Below are the required libraries that are not included in the package and will need to be installed independently:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 (Adjust to match your CUDA version. This library is already included in Colab notebooks)
pip install auto-gptq (Only required if using WizardCoder-15B-1.0-GPTQ model)
pip install accelerate
pip install einops
pip install xformers
pip install bitsandbytesThe settings and parameters for local models are located in local_models.py module and can be adjusted to match your particular configuration or preferences.
Logging
All LLM interactions (local or via APIs) are logged in the bambooai_consolidated_log.json file. When the size of the log file reaches 5 MB, a new log file is created. A total of 3 log files are kept on the file system before the oldest file gets overwritten.
The following details are captured:
-
Chain ID
-
All LLM calls (steps) within the chain, including details of each call eg. agent name, timestamp, model, prompt (context memory), response, token use, cost, tokens per second etc.
-
Chain summary, including token use, cost, count of llm calls, tokens per second etc.
-
Summary per LLM, including token use, cost, number of calls, tokens per second etc.
Log Structure:
- chain_id: 1695375585
├─ chain_details (LLM Calls)
│ ├─ List of Dictionaries (Multiple Steps)
│ ├─ Call 1
│ │ ├─ agent (String)
│ │ ├─ chain_id (Integer)
│ │ ├─ timestamp (String)
│ │ ├─ model (String)
│ │ ├─ messages (List)
│ │ │ └─ role (String)
│ │ │ └─ content (String)
│ │ └─ Other Fields (content, prompt_tokens, completion_tokens, total_tokens, elapsed_time, tokens_per_second, cost)
│ ├─ Call 2
│ │ └─ ... (Similar Fields)
│ └─ ... (Call 3, Call 4, Call 5 ...)
│
├─ chain_summary
│ ├─ Dictionary
│ ├─ Total LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
│
├─ summary_per_model
├─ Dictionary
├─ LLM 1 (Dictionary)
│ ├─ LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
├─ LLM 2
| └─ ... (Similar Fields)
└─ ... (LLM 3, LLM 4, LLM 5 ...)Examples
CLI Output: Prediction of a core temperature using Machine Learning
Below is a machine learning example, BambooAI devising, implementing, comparing and finetuning a different Machine learning models to predict a Core Temperature.

A plot resulting from the first iteration using MLPRegressor model. No need to copy/paste the matplotlib code. Displays on the fly

Now compare to a few other ML models

Follow up question for clarification

A further follow up, asking for clarification

More follow up… Notice the switch to a 16 model as it ran out of 4K window space

Yet more follow up question..

Got sidetracked, and needed a feedback for correction

Final iteration… using the best performing model and tuned hyper parameters. Final R-Squared 0.9166.

Notes
-
The library currently supports OpenAI Chat models. It has been tested with both gpt-3.5-turbo and gpt-4. The gpt-3.5-turbo seems to perform well and is the preferred option due to its 10x lower cost.
-
For coding tasks it also supports SOTA open source code models like CodeLlama and WizardCoder.
-
The library executes LLM generated Python code, this can be bad if the LLM generated Python code is harmful. Use cautiously.
-
Be sure to monitor your token usage. At the time of writing, the cost per 1K tokens is $0.03 USD for GPT-4 and $0.002 USD for GPT-3.5-turbo. It’s important to keep these costs in mind when using the library, particularly when using the more expensive models.
-
Supported OpenAI models: gpt-3.5-turbo, gpt-3.5-turbo-613, gpt-3.5-turbo-16k, gpt-4, gpt-4-0613.
-
Supported Open Source Models: WizardCoder-15B-V1.0, WizardCoder-Python-7B-V1.0, WizardCoder-Python-13B-V1.0, WizardCoder-Python-34B-V1.0, WizardCoder-15B-1.0-GPTQ, WizardCoder-Python73B-V1.0-GPTQ, WizardCoder-Python-13B-V1.0-GPTQ,
WizardCoder-Python-34B-V1.0-GPTQ, CodeLlama-7B-Instruct-fp16, CodeLlama-13B-Instruct-fp16, CodeLlama-34B-Instruct-fp16, CodeLlama-7B-Python-fp16, CodeLlama-13B-Python-fp16, CodeLlama-34B-Python-fp16, Phind-CodeLlama-34B-v2.